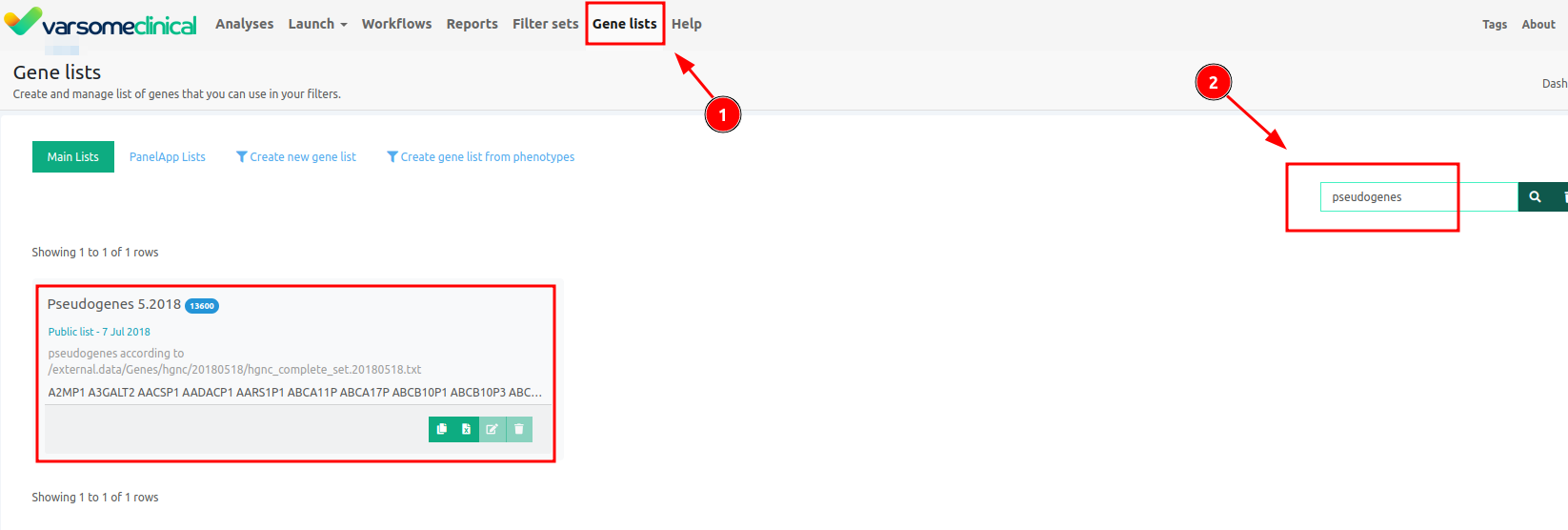
- The list of pseudogenes is obtained from https://www.genenames.org.
- For filtering with pseudogene list you can use dynamic filters (the funnel icon on the left) and select a Gene List filter.
- Or you can perform a Gene List analysis, which creates a sub-analysis like an algorithmic filter.
Where to find the gene list for pseudogenes?
Further Remarks
Question: Can VarSome Clinical recognize if a variant was identified on a functional gene or on a homologous pseudogene? How can I be sure that the variants called in pseudogene rich regions do not derive from the pseudogene?
Answer: That's one of the limitations of NGS sequencing. Pseudogenes are real sequences and are present in the genome. When a read can be perfectly aligned to multiple regions of the genome, as can be the case if a region of a pseudogene is an exact copy of a region of a functioning gene, then what usually happens is that the read is either discarded or marked with a very low score since the aligner cannot know which of the two (or more) matching regions it should be aligned against.
And this isn't a problem that is specific to pseudogenes. There are multiple, real and functioning genes that are very similar to one another. SMN1 and SMN2, for example. One way of to dealing with such duplicate sequences is to mask all such regions and only keep one of them unmasked. Please see Ebbert et al for more details. There is no good solution to this problem, it isn't a limitation of VarSome Clinical, but a direct result of how NGS sequencing works (see, for instance here and here).